Ladybug
Introduction
Ladybug is the debugger of the Frank!Framework. Unlike debuggers of programming languages, you use it to investigate the execution of an adapter after it has run. You have a tree view that shows you how your adapter processed the incoming message. Each time you open a node of the tree, you see more details.
Please do this section after doing section Adapter Status. In particular, you should have processed files example.csv and example2.csv as explained. This way, you have Ladybug reports to examine.
Please start Ladybug as follows:
In the main menu, click “Testing” to open it (number 1 in the figure below).
Click “Ladybug” (number 2).
A happy flow
First examine the execution of example.csv, which went well. Please do the following:
After opening Ladybug, you have the page shown below. You are confirmed that you are seeing Ladybug (number 1). Please go to tab “Debug” (number 2). The other tabs are for advanced features discussed in section Ladybug.
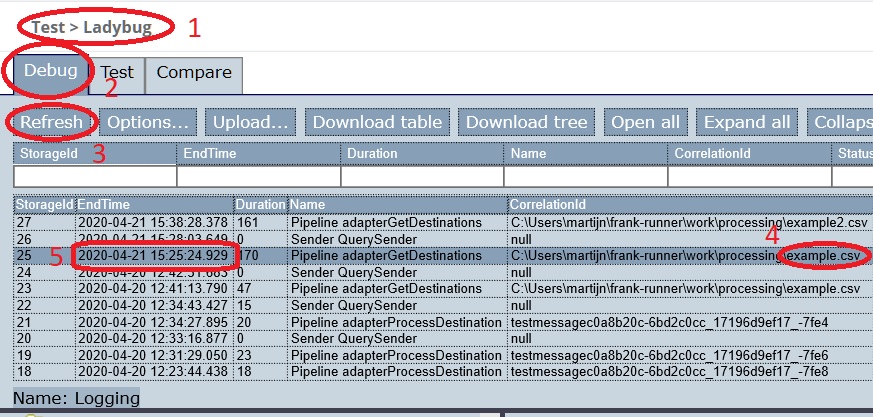
Press “Refresh” (number 3).
You see a table with all adapter runs (test reports), sorted in descending order by execution time (number 5). Select the top-most row in which the “CorrelationId” column shows the text
example.csv(number 4).To the bottom-left, the screen looks like shown below. Please expand / collapse the nodes to reproduce this view.
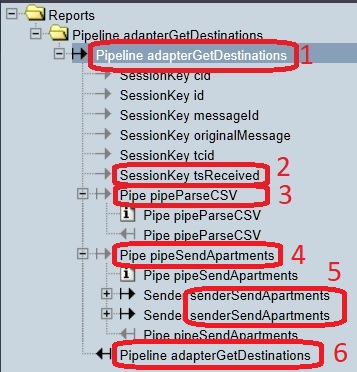
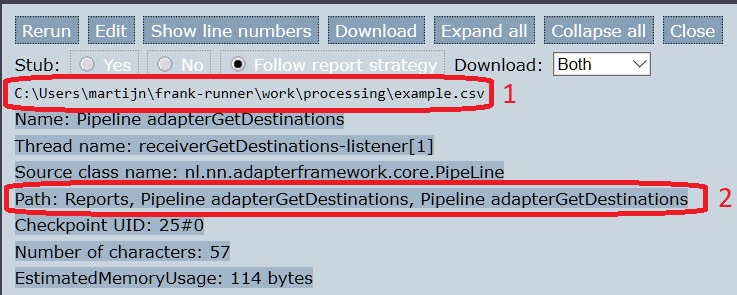
Click node number 1. To the bottom-right, the screen looks like shown below. You see the message that enters the pipeline (number 1). It is the absolute path of the filename being read. You also have it confirmed where you are looking in the tree view (number 2).
Select node 2 in the figure of step 4. The item “tsReceived” is a session key, a data item accompanying the incoming message. To the bottom-right, you should see that the value of this session key is a timestamp. The Frank!Framework automatically adds this session key to the incoming message. It is the time that the incoming message was received.
Select node 3 in the figure of step 4. This is the first pipe in the pipeline. From the figure of step 4, you can see that this pipeline has pipes “pipeParseCSV” (number 3) and “pipeSendApartments” (number 4). To the bottom-right, you see the same file path to
example.csvthat you saw in step 5. The input of the first pipe equals the input of the pipeline.Select node 4 in the figure of step 4 to select the second pipe. The bottom-right looks like shown below. The input of this pipe is the output of the previous pipe. You can see that file
example.csvhas been read and that the contents has been transformed to eXtensible Markup Language (XML). There is much information about XML on the internet.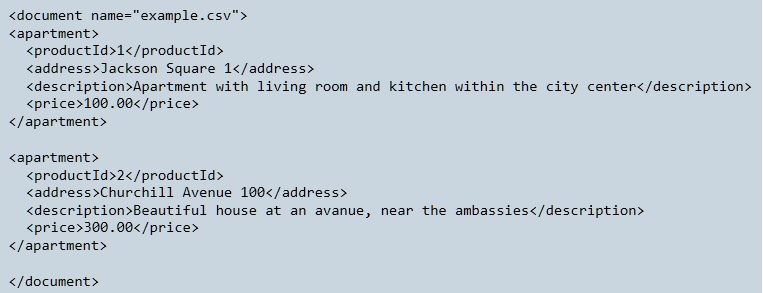
Within the second pipe, a sender named “senderSendApartments” has been invoked two time (figure of step 4, number 5). In the previous step you saw two XML elements with tag
<apartment>. It seems that the configuration iterates over the apartments and sends them somewhere. To learn more, you have to expand these nodes.In node number 6 of step 4, you can see the result of the pipeline, see figure below. You see an XML element with tags
<rowsupdated>. This kind of output is produced when the database is updated.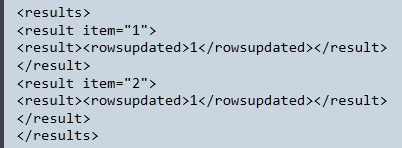
Please expand the top-most sender node (number 5 of step 4), resulting in the figure below. Please expand and collapse the nodes until your screen looks like shown.
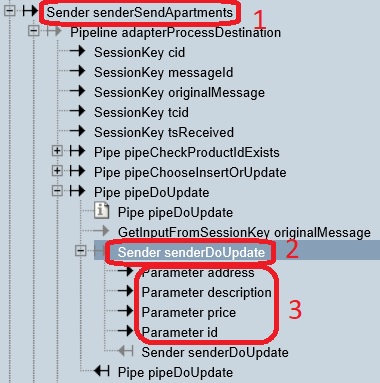
The sender you originally expanded has been annotated with number 1. You see that the other adapter within the NewHorizons configuration is invoked, namely “adapterProcessDestination”. You see that execution arrives at a sender named “senderDoUpdate” (number 2). Expanding this sender shows “Parameter” items (number 3).
Please select number 2 shown in the last figure. The bottom-right looks as shown below:
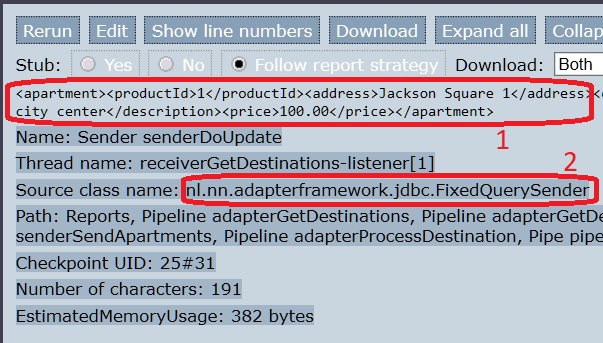
You see an XML snippet with tag
<apartment>. This was produced earlier by parsing CSV fileexample.csv. You also see a Java class namenl.nn.adapterframework.jdbc.FixedQuerySender. This name references the Java class executing the building block you see. This is the confirmation that the database is being modified. The name of the sender issenderDoUpdate, suggesting that an SQL Update statement is being performed. This is indeed the case.Note
If you are examining a Ladybug report and you are not sure what is happening exactly, you can ask the Frank developer who handed you the config under study. If you are a Frank developer yourself, it may interest you that you can lookup the XML of the Frank config within the Frank!Console. In the main menu click “Configuration”.
In the bottom-left, please select the “Parameter” nodes you saw two pictures back (number 3 in that figure). Select them one-by-one to get the values of the query parameters. This shows you what values are being written to the database.
This research can be summarized as follows. The adapter named “adapterGetDestinations” parses a CSV file. It transforms the records to XML, each record being wrapped in a tag <apartment>. For each apartment, the adapter named “adapterProcessDestination” is invoked. The input message of this second adapter is the current <apartment> XML element. For the first apartment, you saw that an SQL Update statement has been performed to write to the database. You found the values being written.
An unhappy flow
Second, examine the execution of example2.csv, which resulted in an error. Please do the following:
Look at the top-left of Ladybug again as shown below. Select the top-most row having a CorrelationId containing
example2.csv. Its Status column should be “Error”.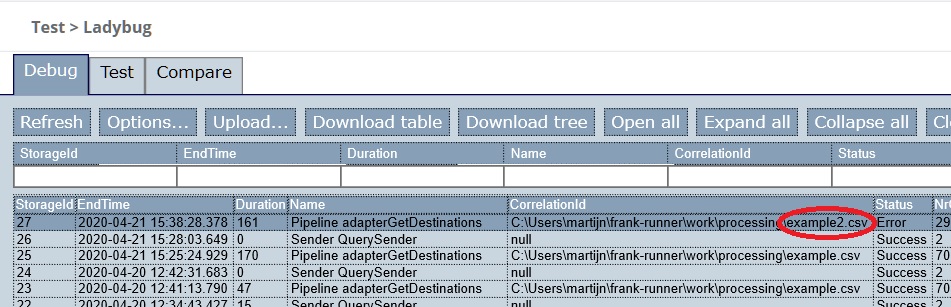
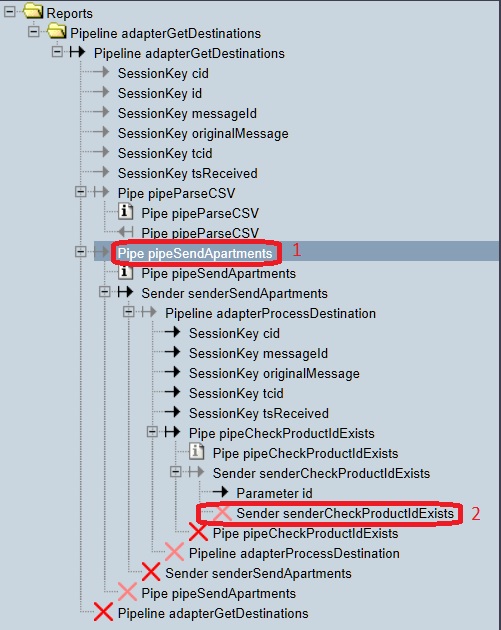
The bottom-left looks like shown below. Please expand/collapse the nodes as is done in the figure. You are focussing on the error this way.
Warning
A red cross means that a Java exception occurred while processing the incoming message. Adapters can also handle errors without a Java exception happening. In such cases, you will not see a red cross, even though processing was not successful. You will not detect all errors when you only search for a red cross.
Select the node numbered 1. You see that the incoming file,
example2.csv, has been read and that the contents has been transformed to the following XML: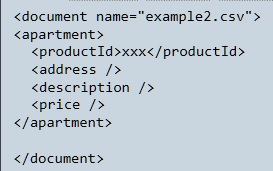
Remember that the contents of file
example2.csvwasxxx. This is only one field instead of the expected four. You see that three empty fields “address”, “description” and “price” have been invented by the transformation to XML.Now select node number 2 from the second-last figure. The bottom-right looks as shown:

We highlight a few keywords within the error. You see the string “FixedQuerySender” at the end of a Java class name. This identifies the Java class that produces the error. It is a class that executes queries on the database. You can see that this sender tries to convert the string
xxxto a numerical value, which fails.
This example should warn you that this configuration is not ready for production. It does not check whether the input is valid. It just carries on with invalid input and it luckily fails somewhere. If example2.csv would have contained the text 1, then updating the database might have succeeded, corrupting your data.
Note
If you are a Frank developer, you may want to know how to check the input. In chapter Getting Started, you can read how to check whether an XML document satisfies an XML schema. After the pipe named “pipeParseCSV”, you can insert a pipe to check whether your XML satisfies an XML schema. In this XML schema, you can check that there are exactly four fields and that the productId and the price are numerical values.